No more hallucinations
Last week we rolled out another safety feature - checking consistency of the response from the LLM with the content it is meant to be using to generate it. This shoud catch hallucinations or when LLM uses it's pre-training to answer a question. But it also catches any prompt injection or jailbreaking - if it somehow got through our other checks.
Checking alignment of LLM Response
Despite clear prompting, LLMs hallucinate. And sometimes use their large training set to answer a question instead of solely using the context provided.
One of the endpoints that AAQ presents is LLM Response. The process diagram on the page will be kept up to date on how the service works but here is what it looks like at the time of writing:
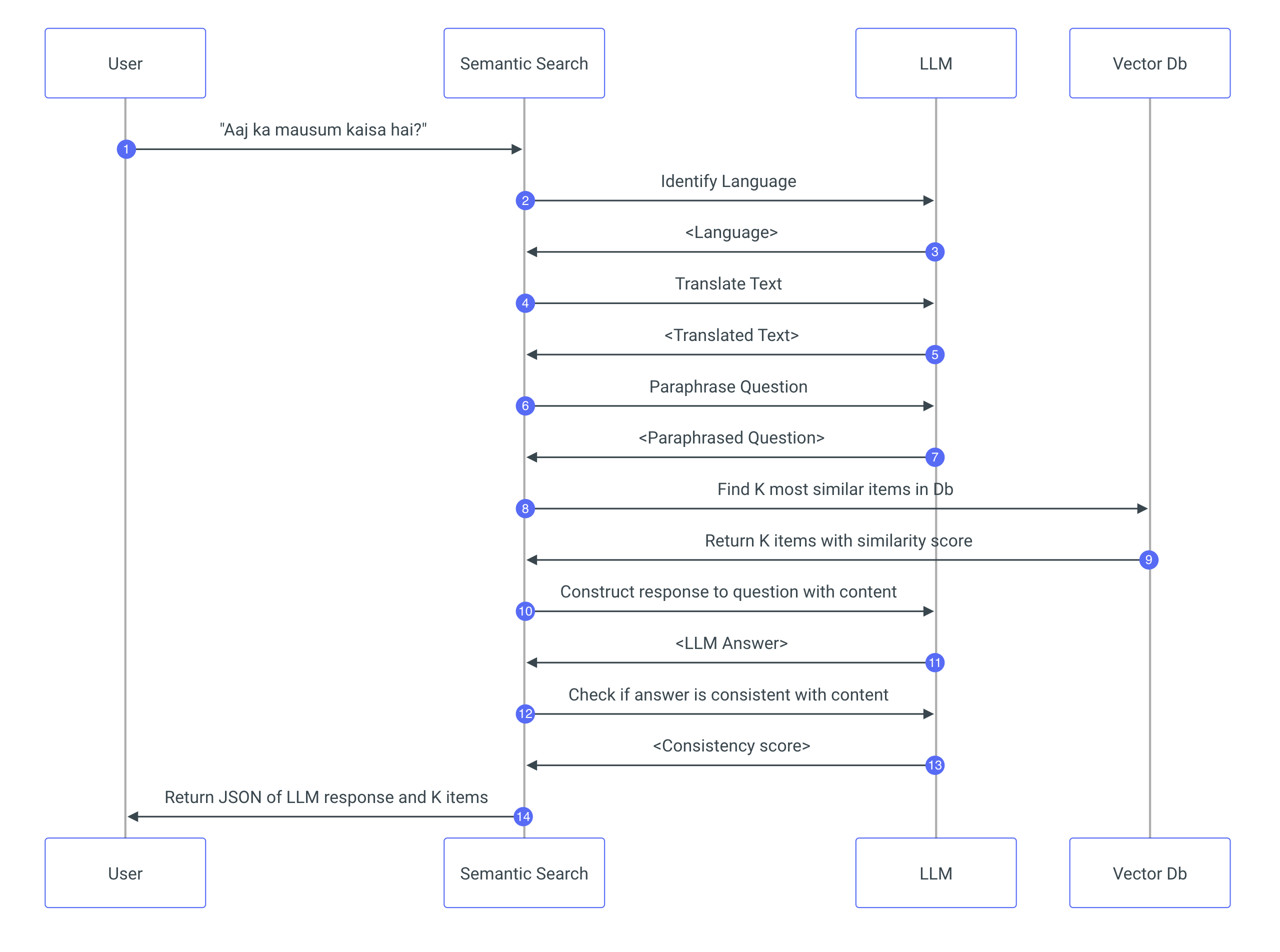
Steps 12 and its response, 13 check if the statements being generated by the LLM are consitent with the content it is meant to use to generate it.
Using AlignScore
We can use GPT4-turbo and it does remarkably well on our test data. But there may be reasons - from data governance and privacy rules to costs - for not sending the data to OpenAI. One option is to use your own locally hosted LLM.
The other option is to use AlignScore, a model built specifically for this use case. It can be deployes as another container that exposes an endpoint that AAQ can call to check consistency.
See docs for how to do this.