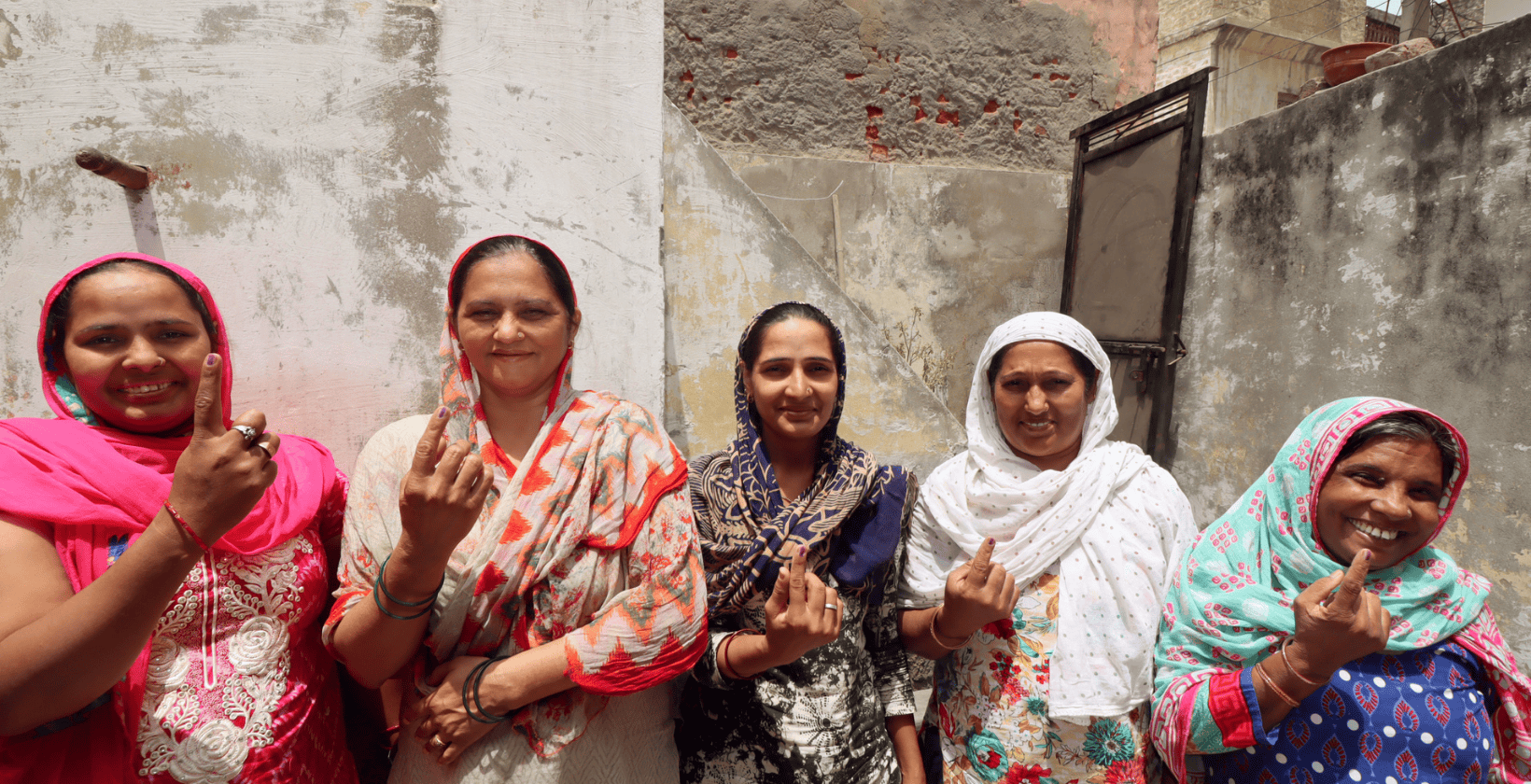Usually, I’d say the question doesn’t even matter. But here’s one that is topical:
“How do you measure impact when the treatment itself is a moving target, evolving alongside the control?”
This comes up constantly in AI evaluation conversations. Traditionally, A/B testing assumes your treatment is consistent across the population. But good tech solutions, and AI products in particular, are constantly evolving. You are (and should be) always experimenting to improve your product.
Creating good surveys is hard. Ask any economist or researcher who’s spent weeks crafting the perfect questionnaire, and they’ll tell you about the countless hours spent hunting through academic papers, existing surveys, and their own memory banks, searching for question formats, flow structures, and methodological approaches that can help them build a cohesive survey. Even when they need to develop original questions, they’re often looking for proven frameworks and industry-standard approaches that can serve as reliable benchmarks for their own work.
SurveyStream is a software product developed by IDinsight to support and streamline primary data collection operations. SurveyStream helps data collection teams manage survey operations more efficiently, freeing up their time to focus on other crucial activities both before and during a survey.
SurveyStream functions as a web application backed by a robust data management system that survey teams can use to manage enumerator hiring, assign enumerators to respondents, send periodic emails to enumerators with their assignments and get timely insights into productivity and data quality.
AI has the power to free up human time and improve lives. Yet it can only do so if it is designed ethically and inclusively. There’s a significant risk that AI will primarily extract from, rather than serve, ordinary people. Just as with the industrial and digital revolutions before, people may become further alienated from the world around them. We want to forestall this, without adding drag to the full and remarkable potential for social impact from technology.
We propose two new principles to drive AI development toward promoting dignity and human connection, ensuring that users - students, patients, citizens - are treated with respect for their humanity. In this fast-moving field we hope these will guide IDinsight’s own work, and we welcome feedback on how to improve them further.
In 2024, elections took place in some 70 countries, home to half the world’s population. In India alone, 642 million people cast ballots1 in the general election, making it the largest democratic exercise in history. Ensuring the smooth conduct of Indian elections for hundreds of millions of people was no small feat and required the dedication of millions of support staff. ] in the general election, making it the largest democratic exercise in history. Ensuring the smooth conduct of Indian elections for hundreds of millions of people was no small feat and required the dedication of millions of support staff.
Our team worked with the government of Uttar Pradesh where millions of registered voters participated in the elections. To support this monumental task, IDinsight developed ElectionGPT–– an AI-powered tool designed to help election officers in India. The tool served as an indispensable resource, answering thousands of questions with speed and accuracy, while saving officials countless hours.